最近、画像生成AI・Stable Diffusionが動く環境を入手したことを書いた。
それに伴い、専用のTwitterアカウントも作った。
作品発表用のPixivアカウントも作った。

あと、noteで色々と試した記録を残している。


そうやってプレイヤーとして色々と試しているうちに、画像生成AIに対する知見や考察も深まってきたので・・・
「画像生成AIは意識進化の夢を見るか?」とタイトルをつけてそれについて書いていこうと思う。
~目次~
・使ってて改めて思ったノイズ問題
・手描きの絵は質が良いのか?問題
・人間が描いた絵と、AIが描いた絵
・画像生成はどんな仕組みで起きる?
・我々がイメージを思い浮かべる時の仕組みは?
・「記憶」と「記録」の差異
・人間が描く絵とAIが描く絵の違い
・「モデル」による違いと、Counterfeitについて
・水彩絵について考える
・こういう絵は面白い?
・複素空間モデルイメージの試作
・結論:画像生成AIは意識進化の夢を見るか?
使ってて改めて思ったノイズ問題
AIについては以前にも書いたことがある。

これは、半田広宣さんの出してきたAI生成画像に対して、自分なりに評価をして分析をしてみたものだったが・・・
気になったのはとにかくノイズの多さだった。

ピクセルノイズ、構図ノイズ、模様ノイズ、色合いノイズ、オブジェクトノイズ・・・とそれぞれ色んな種類のノイズがあることを書いたが、とにかく微妙な構図や模様である所に関してのデザインがぐちゃぐちゃである。
本来はこういう微妙な部分は、作家が自身の身体感覚を使って「なんとなく生理的に良い感じ」に描かれるものなのだが・・・
AI生成画像の場合は乱数表でサイコロを転がすように生成されるものだから、当然のように生理的に悪いものが出てくる。
そのため、技術的には高度で雰囲気は綺麗っぽいが、ノイズが多いみたいな特徴は、AI生成画像において常につきまとう課題となっている。
じゃあやっぱりイラストや画像は手描きが一番でしょう!
ということで、人間が描いたイラストで良いものを探す旅に出かけたかったが・・・
そうすると新たなことに気付いた。
手描きの絵は質が良いのか?問題
人間が描いたもので満足のいくものを探そうとする上で気付いた。
思ったよりも上手くいかない。というか、自分が気に入る良い感じの絵ってなかなかたくさんは見つからない・・・
好みのジャンルが何かによるだろうが、マニアックでニッチな雰囲気の絵を好ましく思うほど、良い絵が見つかることが少ない。
というか・・・
そもそも、人間が描いた絵もノイズが多い
・・・ということに気付いた。
確かに、人間が描いた絵は「作家が自身の身体感覚を使って、なんとなく生理的に良い感じの絵が描かれている」というのはその通りなのだが・・・。それは技術的に優れた作家が時間と体力をたっぷりと使ってやることである。
優れた作家が優れた絵を描くことは当然のように大変であり、体力を使うことである。・・・とくに「体力を使う」という点がネックなのではないだろうか?
そもそも手描きのイラスト生成は、才能ある作家が長年培った技術が必要な上に、十分な体力と時間が必要なものであるため、そこに至るのはレアリティの高いことであるし、体力を使うものなので安定した成果を出すことは簡単ではない。
もちろんあまり体力を使わないで優れた絵を描いちゃうような神絵師や漫画家みたいな人もいるが、作家がたくさん絵を描くときはどこか合理化して描いている所もあるものなので、本当に繊細な絵をコンスタントにたくさん出すことは、稀にいるレベルの天才でないと難しい。
単純にネットで良いイラストを探そうとするとどうなるのか?
そもそもインターネットの強みはネットに情報を自由にアップロードできることであり、イラストが自由にアップロードできる環境は2000年代以前の頃からあったことだが、自由にアップロードができるがゆえに、未熟なイラストもたくさんあるのは当然のことだった。
Pixivやニコニコ静画をざっと見たり、ネットでイラスト収集をしたことがある人なら分かるが、そもそもネット上のイラストというものは「上手い / 下手」で入り混じるノイズの世界である。これはインターネット発展の黎明期の頃からずっとそうである。
対して、AI生成画像の場合は、確かに雑に出力すると雑にノイズのあるものが出力されることもあるが・・・
例えば、自分(Raimu)の環境で以下のように十分なクオリティの画像を一つ出すのにかかる時間は約20秒~30秒である。

AIイラストの強みはとにかく「体力や時間を使わない」で多数のイラストを出力できることであり、「GeForce RTX 4060といったグラフィックボードを入れたパソコン+Stable DifisionといったAI画像生成ソフトウェア」があれば、あとは電気を使って稼働させるだけでどんどんイラストを生成することができる。
これはガソリンがあれば長距離を移動できる車や、電気があれば高度な計算をしてくれる計算機のような発明品の一種である。
だからそうした必要な機器を揃えて、必要な設定をしてからボタン一つ押せば技術的に優れた絵ができる。
あとはボタンを何回も押せば良い。ガチャを回すように何回も何回も押す・・・
そして、何回も押して良い絵を選別すると、世界に一つだけのものとして生成された良好なイラストを手に入れることができる。
人間が描いた絵と、AIが描いた絵
以上のように、AI生成画像にもノイズが多いし、手描きにもノイズが多い・・・ということで・・・
AI生成画像も良いな!となるわけである。
そうなると、手描き画像とAI生成画像にはそれぞれの特徴があるため、それが大事になってくる。
まず、「低品質な絵の特徴」がそれぞれ違う。
ネット上のイラスト(例えばPixivやニコニコ静画にあるもの)の低品質なものは「落書き」みたいな感じであり、人の身体が下手なりに崩れていたり、あまり作り込まれてなかったり、そもそもの出来が悪かったりする。
しかし、AI生成画像の低品質なものはAI特有のノイズがあったりして気色悪いかもしれないが、技術的にはやたらと高く、インパクトだけは強い雰囲気のものが出てたりする。
また、「高品質な絵の特徴」ももちろん違う。
手描きで高品質な絵は本当に人間にしか描けないオリジナルで、かつ複雑な模様でも統合されてて美しいものが描ける。
AI生成画像も不自然さがほとんどないものを出すことが可能だが、どこかしらに存在している画像をベースにしているので、ネットにほとんど無いものを参考にしてひねり出したオリジナル作品みたいなものは作れない。ネットには上がっていないような人間の体験をベースにした作品が出てくることは絶対にあり得ない。
以上のような特徴は、例えばPixivとCivitaiを比較してみたりしたら分かると思う。
イラストサイト代表:Pixiv

AI生成画像用サイト:Civitai

AI生成画像にはそんな特徴がありながらも、それを好む人がやっているのがAIイラスト界隈というわけである。
AIイラストはあくまでそうしたものを好むユーザー向きのものなので、好まない人は好まないだろう。
そもそもオタクはK-POPのコンテンツとかTiktokの動画は見ないように、(たぶん)K-POPとかTiktokが好きな女子高生はAIイラストは見ない。
各々がそんな自由意志にゆだねられている上で流行っているのが、SNSが普及している時代における流行である。
画像生成はどんな仕組みで起きる?
さて、画像生成AIについて考えるために、その仕組みについてちゃんと知っておこう。
・・・といってもそのすべてを知ろうとすると、専門的で難しい話になる上に、あんな技術やこんな技術の色んな話が出てくるので大変なことになる・・・
とりあえず基本はニュートラルネットワークとディープラーニングであるため…
それについて説明をしよう。
以下の本を参考にする。

まず、ニュートラルネットワークとは・・・
簡潔に言うと「人間の脳の構造を模した数理モデル」である。
これは「ニューロン」と呼ばれる計算ユニットを持っている生物の神経系のメカニズムを模倣している。
以下のように一個一個のニューロンのような要素が繋がっていて、それぞれの「関係性の強さ」が違っている。
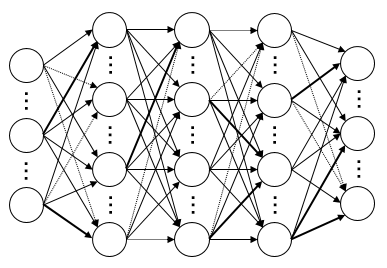
関係性の強さは「重み」のような概念で表され、それぞれがどれほど強いかは事前に学習した結果によって算出される。
基本的なニュートラルネットワークの場合、以下のように「入力層」「中間層」「出力層」があり、
何かしらの入力に対して出力が行われる。
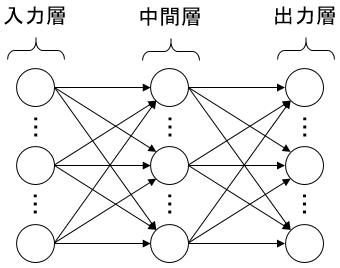
こうしたニュートラルネットワークのモデルに関しては、実は2000年以前にも既にできていた発想だった。
しかし、使い道がよく分かっておらず、現在のようにこれによって高度なAI(人工知能)が作られるには至っていなかった。
それから、2000年代の後半あたりから「中間層をとにかく多層化してみよう」というアイディアが導入されるようになった。
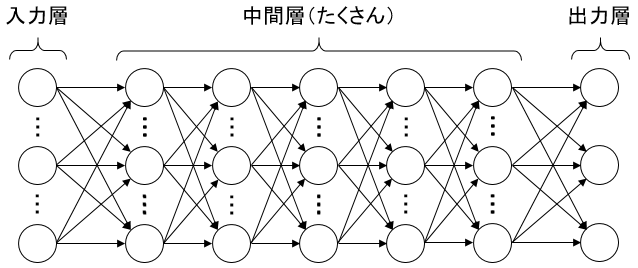
これが可能になった理由として大きいのはコンピューターの性能の向上である。
2000年代はコンピューターがどんどん進化していった時期である上に、学習のための大量データの入手が容易になっていったので、このアイディアがよる高速な機械学習の精度がどんどん向上していった。
それによって出来たのがディープラーニング(別名、深層学習)によるAIであり、そこからAI開発が飛躍的に発展していくようになる。
実際にこれを作って人間が扱う言語を学習させて、人間が望むレベルの返答ができるかどうか試してみた所・・・何故か良い結果が出たのでこのやり方なら成功するということで研究が進むようになった。
・・・そう。何故か良い結果が出たのである。
ニュートラルネットワークとディープラーニングによって人間の脳を模倣(完璧な模倣ではない)したAIはブラックボックス的な特徴があり、何故良い結果が出るかは完璧には解明されていないことを知っておこう。
こうした画期的な技術によって2010年代はさらにAIが飛躍的に進化していき・・・
2015年に「DeepDream」ができたり、2016年に「アルファ碁」ができたり、2017年に「DeepL翻訳」ができたり・・・
そして、2022年7月に「Midjourney」がリリースされ、2022年11月に「ChatGPT」がリリースされたりと・・・AIがどんどん注目される時代になっていった。
今では「AI=ディープラーニングを用いた人工知能」であることが当たり前である。
それから、ディープラーニングを用いたAIによって人間が望んだ通りの結果を出すためには、はじめに大量のデータを学習させる必要がある。
例えば、AIで画像を生成したい場合、まずは大量の画像の「記録」を読み込ませ、「入力⇒出力」を繰り返し、ディープラーニングによる機械学習を行う。
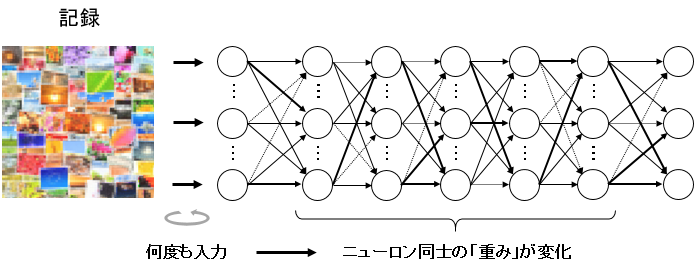
そうして学習済となったニュートラルネットワークは大量の「ニューロン」と「ニューロン同士の関係性の強さ(重み)」のデータを持ち、人間が望む結果が出るレベルまで賢くなる。
それに対して画像を入力すると、入力した画像がどんな内容のものなのか、層ごとに認識を深めていくように何の画像か判断することができる。
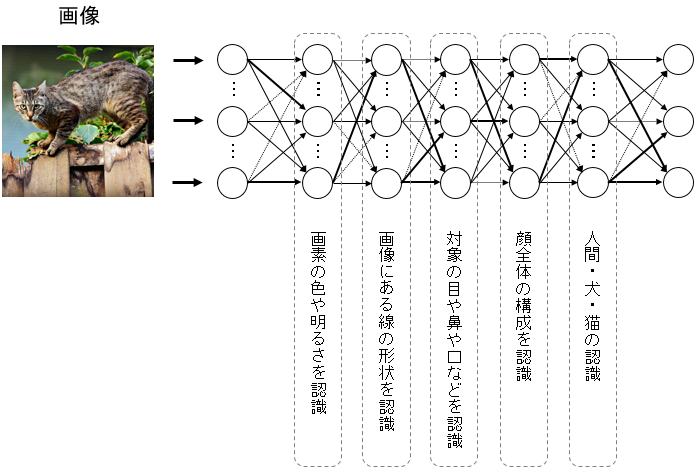
そして、これを使って画像生成をする場合は、ディープラーニングによる学習結果と画像生成のアルゴニズムを使っていくことで、AIによる画像生成が行われるわけである。
かなりざっくりとした説明であるが、大体分かっただろうか?
我々がイメージを思い浮かべる時の仕組みは?
それから、我々人間がイメージを思い浮かべる時の仕組みというのがある。
人間が何か「絵を描こう」と思った場合・・・
ざっくり言うと「記憶」からイメージを取り出すことからはじまり・・・
作りたいものをぼんやりイメージし、さらに具体的な形にして・・・
さらにもっと具体的な完成品を思い浮かべて、描き上げていくことで最終的に完成する。
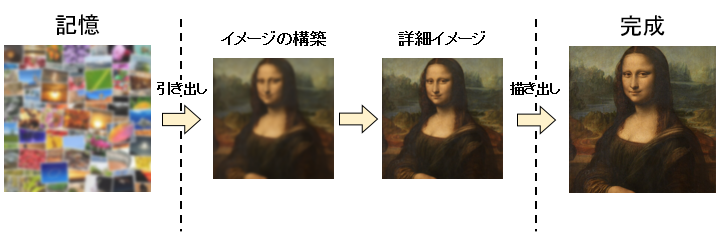
ここで少し話を変えて・・・
神秘思想とか西洋魔術で有名なカバラという宇宙論だと、人間の世界がこの世に生成されるプロセスの中に「元型界」「創造界」「形成界」「物質界」と呼ばれるものがあるとされている。
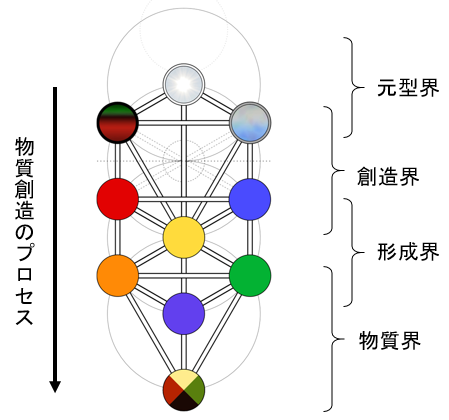
絵のイメージが完成するプロセスもざっくりとそれが当てはまることになる。
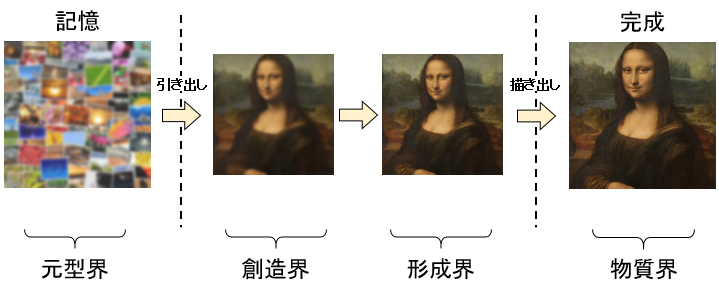
「絵師」や「画家」といった絵の専門家はこのイメージをなるべく高精度で思い浮かべて、描きたい絵を脳内で構築し、描き出すことに長けているわけである。
また、これが画像生成AIの場合は「記録」と「記録から行った機械学習」と「画像生成アルゴニズム」といったもので画像を生成していくわけだが・・・
ざっくり整理すると以下のようになるだろう。
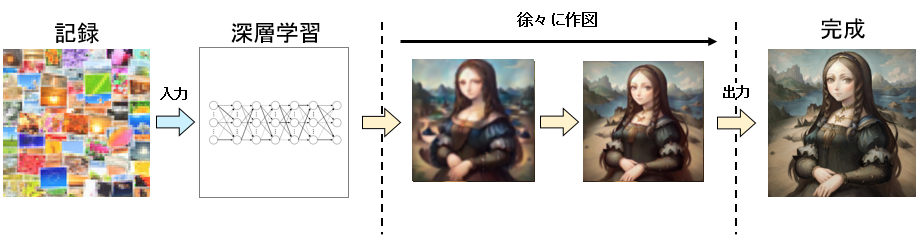
こうすると、人間が画像を生成するプロセスと、機械が画像を生成するプロセスがなんとなく似ていることが分かるだろうか?
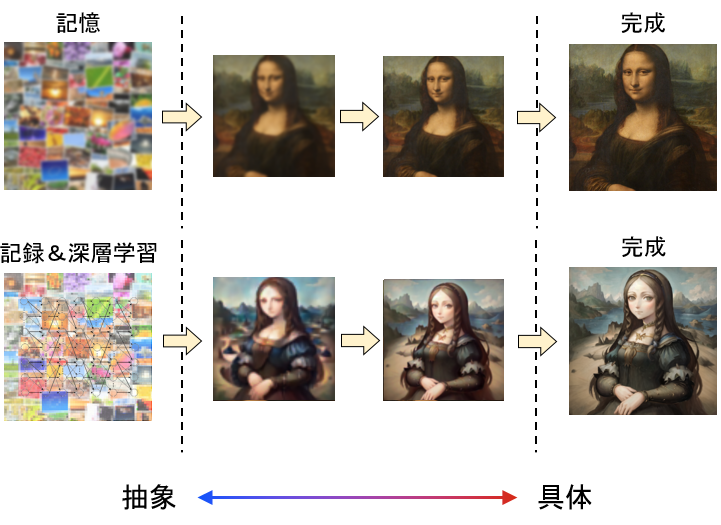
「記憶」と「記録」の差異
ここで、「記録」と「記憶」の違いにも気を付けておこう。
人間が記憶から絵を引き出した場合と、コンピューターが記録から絵を生成する場合・・・
両者はそれぞれ同様のように図を描いたが、根本的に次元が違うように別物である。
「記録」は客観視できるようなコンピューターの世界にあるが、
「記憶」は各々の「身体感覚」の中にある。
この違いが重要である。
例えば、我々がリンゴを見た場合、その瞬間において「リンゴがある」と認識するわけだが、その一瞬の前には「リンゴがあった」という記憶があるから、「リンゴがある」と認識できるわけである。

そこからリンゴが何かしらの理由で移動したりした場合は、「過去にリンゴがあった」という記憶から「リンゴがなくなった」と認識する。
このように「我々の身体感覚の中にあるもの」が「記憶」であり…
それはコンピューター上に存在する「記録」とは大きく異なる次元にある。
コンピューターと人間の違いを考えるにおいて、その原理を理解しておこう。
人間が描く絵とAIが描く絵の違い
以上のことを踏まえつつ・・・
改めて、人間が描く絵とAIが描く絵の違いについて考えてみよう。
まず、人間が絵を描く場合は以下のようになるわけだが・・・
重要なのは「記憶」の領域から取りたいイメージを出す時に、何かしらの「志向性」があることである。
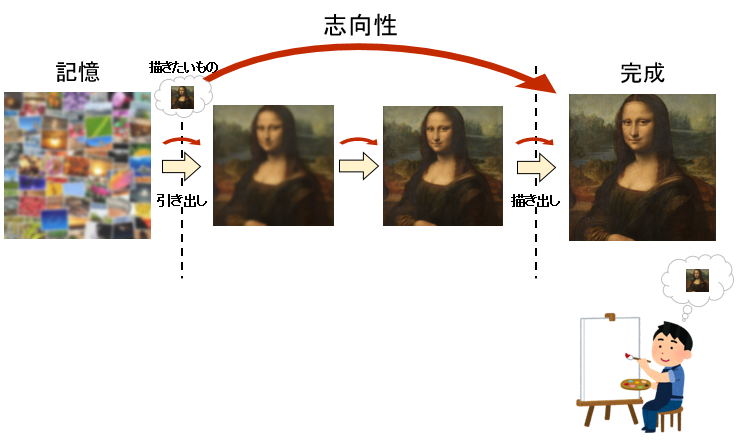
当たり前だが、人間が絵を描くときはまず描きたい絵を構図から決めて思い浮かべていく。
それから、細かい所のデザインを決める場合も、やはり「このように描きたい」と意志を持って決めて、さらに「生理的に良い感じ」になるようにデザインを決めて絵に描き起こしていくこともできる。
記憶からイメージを正確に引き出して、かつ正確に描き出すには「技術」と「体力」がいる点がネックであるが・・・
その能力で志向性を持ちながら「描きたい絵」に向かって絵を描くことができる。
こうしたごく当たり前の特徴は、人間と機械と比較した場合は重要なものになる。
一方で、AIが絵を描く場合は以下のようになる。
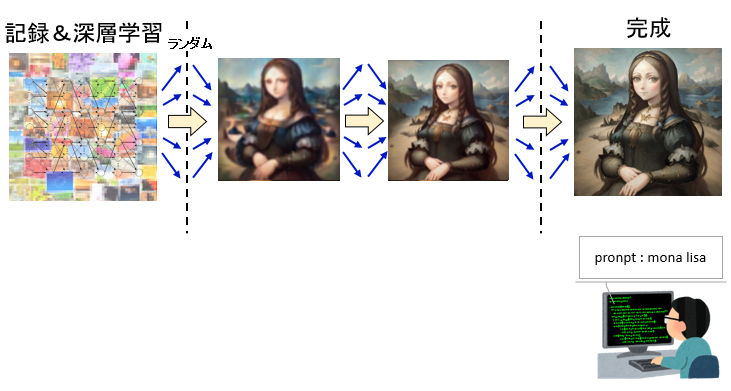
「記憶」から絵を作る人間と同様に、AIは「記録」から絵を作っていくわけだが・・・
その時に「志向性がない」所が重要であり、サイコロで決めたようなランダムな結果から最終的に描く絵を決めていく。
さらに、細かいデザインを決める所も人間のようにはできないため、ランダムに出したデザインが採用されるような結果になる。
だから良い結果が出るかどうかは完全に運任せであり・・・まるでガチャのようである。
こうした志向性のなさがAIのノイズの原因であり、
コンピューターがランダムでノイズを作るのと、本質的に同様のことをAIはやっているような所がある。

ただ、こうした志向性の無さを補うために、人間が出したい絵を「プロンプト」と呼ばれる命令文で指定する。
(例えば、モナリザの絵を描いて欲しい場合は[mona lisa]と指定し、黒髪の魔女の絵を描いて欲しい場合は[1girl, witch, black hear]と指定するなど)
だからある程度の志向性は持っているのだが・・・
しかし、プロンプトで指定した範囲内でランダムに決めて出すことしかできないし、プロンプトにない絵を出す場合もランダムに決めるしかない。未熟なAIだとプロンプトとは違う画像が出てくることもある。
以上の仕組みを踏まえると、AI絵のノイズの多さと虚無感の原因がなんとなく分かるのではないだろうか?

「モデル」による違いと、Counterfeitについて
さて、こうした画像生成AIは何かに使えるのだろうか?
もっと言うと、ヌーソロジーでやりたいような意識進化とか反転とかに何か役立つのか?
を突き詰めるためにもっと考察を深めていきたい。
まず、AI生成画像にはさまざま絵柄がある。
例えば、半田広宣さんがChatGPTでよく出していたようなCG風。
ネットでよく見かけるアニメ絵風。
アニメ絵ではないけどよく見かける美少女イラスト風。
そして、自分がよく出してる水彩絵風・・・などがある。

その他にも色んな絵柄を出すことが可能だが・・・
絵柄の種類は使用しているツールだったり、ツールでどういう絵柄を指定して出すかによって変えることができる。
ちなみに、アニマンダラ先生によると、「Stable Diffusion」と「Midjourney」と「ChatGPT(+DALL-E 3)」にはそれぞれ以下のような特徴があるらしい。
アニメ絵、漫画絵は、
Stable Diffisionが一番だね。
世界のアニメファンや、漫画好きが、目の色変えて(笑)チューニングしているからライム君向きやね。
規制ゼロでヤバイ面もあるが。Midjourneyはアート系に特に強く、一番絵柄の幅が広い。
chatGPTは、日本語文章可能でとにかく使いやすい。
— アニマンダラ屋 (@animandala) January 22, 2024
アニメ絵、漫画絵は、
Stable Diffusionが一番だね。
世界のアニメファンや、漫画好きが、目の色変えて(笑)チューニングしているからライム君向きやね。
規制ゼロでヤバイ面もあるが。Midjourneyはアート系に特に強く、一番絵柄の幅が広い。
chatGPTは、日本語文章可能でとにかく使いやすい。
そして、その中で自分が好んで使っているのは、
Stable DiffusionでCounterfeit-v2.5というモデルを使う組み合わせである。

そもそも、Stable Diffusionが多彩な絵が出せる高性能な画像生成AIを持つソフトウェアなのだが、
これは「モデル」と呼ばれる追加機能を設定することで様々な絵柄の絵を出すことができる。
例えば、「SukiAniMix」のモデルを設定するともっと美少女イラストっぽいものが出るし、
「FlatpieceCore」のモデルを設定すると、輪郭のくっきりしたアニメっぽいものが出るし、
「SukiYakiMix」のモデルを設定すると、ちょっとパステルでファンシーなものが出る。
さらに、「CityEdgeMix」といった実写系モデルを設定すると、写真のような画像まで出すことができる。

AI生成画像を出す手段はStable Diffusion以外にも色々とあるが・・・
個人的に出したい画像はStable Diffusionでなくては駄目で、しかもCounterfeit-v2.5のモデルを使わないといけない・・・
・・・ということで、わざわざStable Diffusionが動くPCを購入して、今はCounterfeit-v2.5を使うことにハマっているわけである。
これは自分なりのこだわりである。
Counterfeit-v2.5は美少女イラストを水彩絵風にして出すのと、水彩絵の背景を描くことに長けたモデルである。
これを使っているうちの思ったのは・・・
水彩絵が面白いのでは・・・?
ということなので、これについて考察してみよう。
水彩絵について考える
水彩絵の特徴は何か?
絵の細かい部分が微妙に曖昧になっている所である。

水彩絵は「水」を使って描くだけあって、細かい所は水のように曖昧にしてぼかして描く特徴がある。
そのため、AI特有のノイズがあった場合でも、「水彩絵の雰囲気」でごまかすことができる・・・みたいな特徴になっている。
あと、そもそもデジタル作画が普及する前、古典的なやり方でカラーの絵を描く場合は水彩絵が主流という点も大きいだろう。
(他の手段だとアクリル画や油絵などが挙げられるが、その辺りになってくると絵の具がちょっと高価といった制約がつく)
つまり、原初の人間がイメージを絵に描き起こす場合、水彩絵は割と親和性が高いのである。
これがアニメっぽい絵になってくると、描かれているもののイメージが水彩絵よりもはっきりしてくる。

つまり、これを先の図に当てはめて考えると・・・
水彩絵の方が「抽象」に近くて、アニメ絵の方が「具体」に近いみたいな位置づけになる。
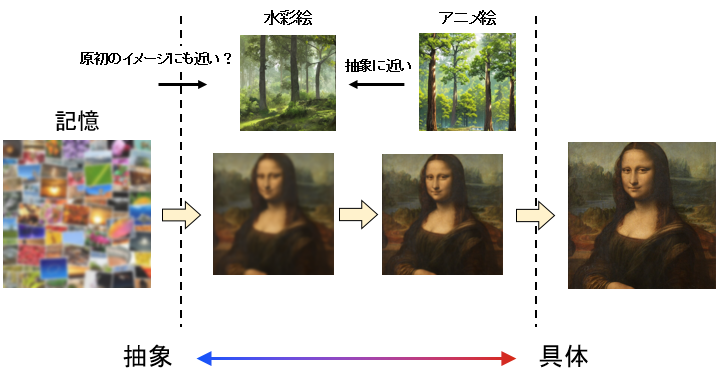
「具体」に近いものがノイズを起こすと違和感の強いものができてしまうが…
「抽象」に近いものがノイズを起こすと、自然に近いものとしてノイズが緩和される。
また、「人間がイメージを起こす時のプロセス」について意識したい場合、
「抽象」に近い水彩絵の方が原初のイメージに近い。
「具体よりも抽象に近い」所がポイントで、こうした絵柄のイメージだと、ヌーソロジーにおける「反転」みたいに、人間が認識しやすいイメージから脱却する方向性のものと相性が良い。
以上のことから、絵のジャンルの中でも水彩絵は面白いのではないだろうか?
この絵は面白い?
画像生成AIを使ってみて、単純にこうすると良さそうだと思った使い方は・・・
「単純に森を出力する」ことである。

水彩絵で森を出すだけでもどこか風情があると思うのだが・・・どうだろうか?
AIの弱点はノイズだということを先ほど説明したが・・・そうなると実は森のような自然物とは相性が良いのかもしれない。
なぜなら、自然にある森もそもそもノイズの産物であることが同様だからである。
そもそも、自然物というものは・・・例えば、木とか草花といったものにはそれぞれ単体だと固有の仕組みや秩序みたいなものがあるが・・・。「どこで生えるか」とか「どこで咲くか」といったことに関しては完全にランダムである。種がどこに落ちるかは運任せみたいなことには変わりはない。
だから、森のような自然の風景の場合は、どこに生えてるかのノイズ(構図ノイズやオブジェクトノイズ)があっても人間は特に気にはならない。
だからこうした自然物とAIは相性が良いということになるわけである。
ちなみに、水彩絵でなくアニメ絵にすると、以下のようになる。

見ての通りアニメっぽい感じにはなったが、違和感はそんなにないのではないだろうか?
ただ、先も説明した通り水彩絵の方が面白そうなので、水彩絵で進めていこう・・・
自分が特に気にいったのは、「夜の森」を出すことである。

こうするとまた独特な面白味が出る。
ヌーソロジー的には、夜は『人間の外面』の表れと言われているため、「影のように暗いもの」と「人間の世界の外」は親和性がある。
だから夜の世界を出力するとそれに付随した良さを出すことができるのではないだろうか?
◆シリウスファイル解説—マクロ宇宙も単なる時空として見ちゃいけない – cave syndrome
OCOT情報も、昼と夜は「対化」の表現だと言っていた。昼は人間の内面で、夜は人間の外面の現れだってこと。確かに、人間は昼間は客観世界(延長)の中で生き、夜は主観世界(持続)に生きるのが基本。これは表相が等化された世界と、表相を中和した世界(表相の等化を無効にする)の関係と言っていいかもしれない。
こうした絵をちょっと加工したり、手作業で色を加えたりすると以下のようになる。





複素空間モデルイメージの試作
ヌーソロジー学習テキスト『変換人型ゲシュタルト論』にて、
ヌーソロジー的な複素平面にイメージを付随させるようなことをやった。
そして、以下のようなイメージ画像を作った。

これを試しにAIを使って・・・「昼の森」と「夜の森」をそれぞれ作ってやってみると以下のようになる。



うーん・・・
試作という感じであるが・・・どうだろうか?
結論:画像生成AIは意識進化の夢を見るか?
さて、最後にタイトルである「画像生成AIは意識進化の夢を見るか?」の結論について書こう。
画像生成AIは「志向性」を持たず、機械的なサイコロを振るようにランダムに画像を出力することしかできない・・・ということを以前に説明した。
だからAIが意識進化の夢を見るかは言語道断で「そんなわけない」が結論として当然になるわけだが・・・
そのプロセスを見て「人間が何をするか」が肝になるのではないだろうか?
以前に『AI生成画像とヌーソロジーについて書く』でも少し書いたが、アニマンダラ先生が言ってた通り、AIとヌーソロジー的な意識進化の関係づけるには、「AIを通して我々人間の意識が発生するプロセスに気づくこと」が重要になってくる。
むしろ我々人間こそAIのように思考することがある生き物だし、AIの思考は人間の思考を模しているからこそ、人間がどう思考しているかに気づくことができるのである。
したがって、AI絵を「見る」のではなく、「想起する」みたいな使い方をすると…
意識進化のためのものとして面白みが出てくるのではないだろうか?
結局、AIはただ機械的に処理するだけのものなのでそれ単体では意識進化の道は開かれない・・・
これはコンピューターでVR(仮想現実)を作った場合もそうである。
それを使った人間が自身でどういうイメージを作り出すかによって、意識進化の道が開かれるのだろう。