最近、AI(人工知能)の目まぐるしい進化によって、「これからはAIの時代だ。」と期待が高まり、AIがますます注目されているような状況になっている。
しかし、そうしたAIが普及する世の中になる中で、AIに対して妄信的になったら良くないし、かといって警戒して距離をとって何も知らないままでいるのも良くないし、AIに対して嫌悪しかない状態になるのも良くない。
そうしたAI時代の波に呑まれないようにするためにも、ここで改めてAIの仕組みについてを説明しておこう。
AIに関しては、以前にも以下の記事で書いたので、その一部の内容を流用して説明しようと思う。
この記事の中にある「画像生成はどんな仕組みで起きる?」の所は、我ながらかなりよく説明できたと思ったが、記事全体の内容は長く混みいったものになっていて難しい・・・
なので、その部分だけ抽出して、ここで別の記事としてまとめ直しておくことにする。
画像生成はどんな仕組みで起きる?
まず、AIといったらテキスト生成AIや画像生成AIなど、その用途には様々なものがあるが・・・
その元となっている仕組みは概ね同じなので、ここでは画像生成AIの仕組みを例に説明していく。
・・・といってもそのすべてを知ろうとすると、専門的で難しい話になる上に、あんな技術やこんな技術の色んな話が出てくるので大変なことになる・・・
とりあえず基本はニュートラルネットワークとディープラーニングであるため、それについて説明をしよう。
以下の本を参考にする。

まず、ニュートラルネットワークとは…
簡潔に言うと「人間の脳の構造を模した数理モデル」である。
これは「ニューロン」と呼ばれる計算ユニットを持っている生物の神経系のメカニズムを模倣している。
以下のように一個一個のニューロンのような要素が繋がっていて、それぞれの「関係性の強さ」が違っている。
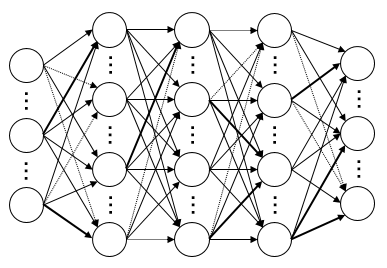
関係性の強さは「重み」のような概念で表され、それぞれがどれほど強いかは事前に学習した結果によって算出される。
基本的なニュートラルネットワークの場合、以下のように「入力層」「中間層」「出力層」があり、
何かしらの入力に対して出力が行われる。
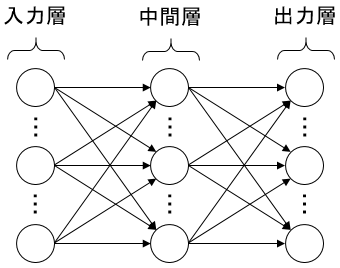
こうしたニュートラルネットワークのモデルに関しては、実は2000年以前にも既にできていた発想だった。
しかし、使い道がよく分かっておらず、現在のようにこれによって高度なAI(人工知能)が作られるには至っていなかった。
それから、2000年代の後半あたりから「中間層をとにかく多層化してみよう」というアイディアが導入されるようになった。
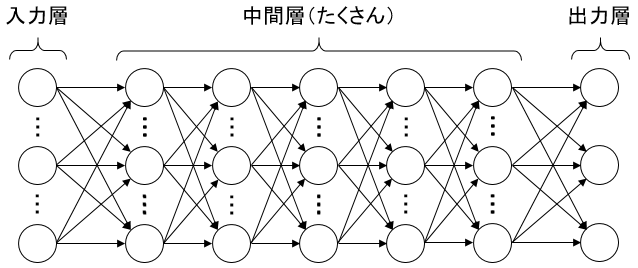
これが可能になった理由として大きいのはコンピューターの性能の向上である。
2000年代はコンピューターがどんどん進化していった時期である上に、学習のための大量データの入手が容易になっていったので、このアイディアによる高速な機械学習の精度がどんどん向上していった。
それによって出来たのがディープラーニング(別名、深層学習)によるAIであり、そこからAI開発が飛躍的に発展していくようになる。
実際にこれを作って人間が扱う言語を学習させて、人間が望むレベルの返答ができるかどうか試してみた所・・・何故か良い結果が出たのでこのやり方なら成功するということで研究が進むようになった。
・・・そう。何故か良い結果が出たのである。
ニュートラルネットワークとディープラーニングによって人間の脳を模倣(完璧な模倣ではない)したAIはブラックボックス的な特徴があり、何故良い結果が出るかは完璧には解明されていないことを知っておこう。
こうした画期的な技術によって2010年代はさらにAIが飛躍的に進化していき・・・
2015年に「DeepDream」ができたり、2016年に「アルファ碁」ができたり、2017年に「DeepL翻訳」ができたりする。
そして、2022年7月に「Midjourney」がリリースされ、2022年11月に「ChatGPT」がリリースされたりと・・・AIがどんどん注目される時代になっていった。
今では「AI=ディープラーニングを用いた人工知能」であることが当たり前である。
それから、ディープラーニングを用いたAIによって人間が望んだ通りの結果を出すためには、はじめに大量のデータを学習させる必要がある。
例えば、AIで画像を生成したい場合、まずは大量の画像の「記録」を読み込ませ、「入力⇒出力」を繰り返し、ディープラーニングによる機械学習を行う。
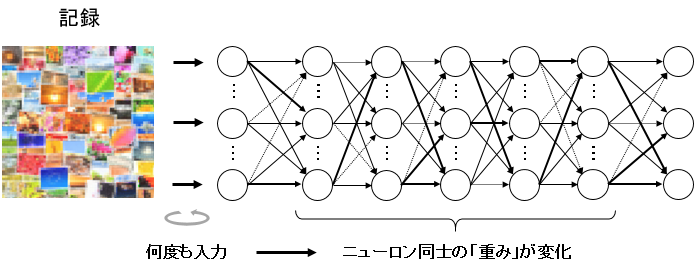
そうして学習済となったニュートラルネットワークは大量の「ニューロン」と「ニューロン同士の関係性の強さ(重み)」のデータを持ち、人間が望む結果が出るレベルまで賢くなる。
それに対して画像を入力すると、入力した画像がどんな内容のものなのか、層ごとに認識を深めていくように何の画像か判断することができる。
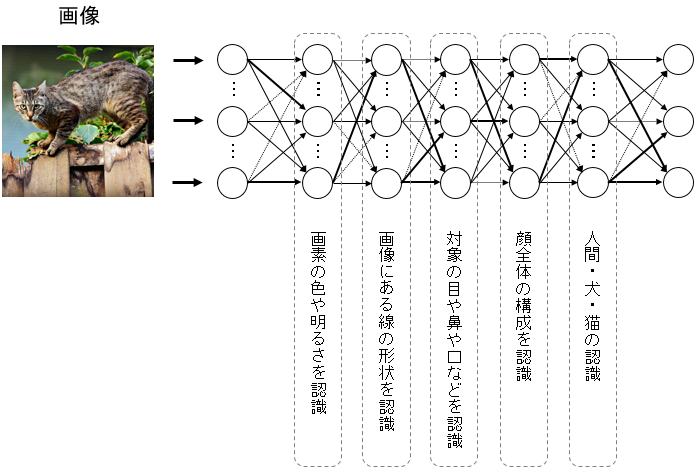
そして、これを使って画像生成をする場合は、ディープラーニングによる学習結果と画像生成のアルゴニズムを使っていくことで、AIによる画像生成が行われるわけである。
かなりざっくりとした説明であるが、大体分かっただろうか?
テキストの場合も同様
以上で説明したのは画像生成AIについてだが・・・
テキスト生成AIに関しても概ね同様と思ってもらって良い。
テキスト生成AIはテキスト出力ができる汎用的なAIであり、GoogleのChatGPTや、MicrosoftのCopilotなど、テキストベースで会話が可能なAIもそれに該当する。
これもあらかじめ大量の情報が入力されていることが前提にある。
画像生成の場合は一個一個のニューロンに画像生成のための情報が入っているが、テキスト生成の場合は一個一個のニューロンにテキスト生成のための情報が入っているわけである。
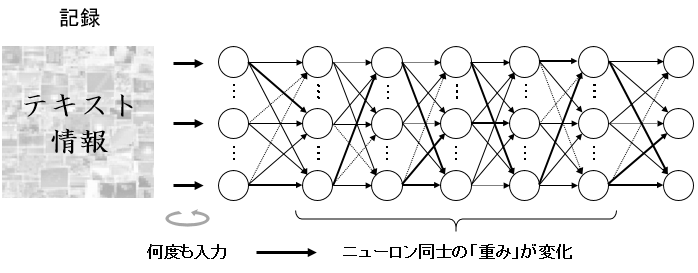
あらかじめ大量の情報を入力しておく際に、どこからどんな情報が入力されているかについては諸説あるだろうが・・・
ChatGPTのようなAIの場合、Google検索で出てくるようなネット上の情報があらかじめ入力されていて、その内容をまとめるようなことが多いと理解しておくと良いだろう。
最近では音声で会話ができるアプリまで出てきている。

こうしたAIは、我々の言葉に対してすごくそれっぽい返答をするが・・・あくまで「学習した情報を元に機械的に出力してるだけ」である。
そのことを肝に銘じておこう。
会話のようなことができるとはいえ、あくまで機械である。
あくまで機械的なものではあるが、情報をまとめることに関しては非常に優れているので、ざっくりした情報を知るのにとても助かることもある。
例えば、スマホにChatGPTのアプリを入れておいて、難しい哲学の用語の質問などをするといくらでも返ってくるため、ざっくりとした哲学の勉強までだったらそれで可能である。

AIの話はつきつめると深く長い話になりそうだし・・・今現在で最重要な哲学はAIについても考えることを含んだ哲学になるだろうから、まだまだ色々なことが言える分野だが・・・
ひとまず、仕組みを知っておいた上で、ツールとして使うことがに大事なるだろうと思う。